Интернет. Поиск и просмотр информации
• Что такое протоколы связи и каково назначение протоколов TCP/IP.
• Различия видов доступа и способов подключения к Интернету.
• Назначение прикладных протоколов Интернета.
• Назначение различных сервисов сети Интернет.
• Что такое World Wide Web, каковы основные компоненты этой технологии.
• Что такое Java-технологии и каковы перспективы их применения.
• Систему адресации информационных ресурсов в Интернете.
• Порядок использования web-обозревателя Microsoft Internet Explorer для поиска и просмотра информации в Интернете.
• Порядок использования Offline-браузера WebZIP для загрузки web-сайтов.
В настоящее время интенсивно развивается Интернет - компьютерная сеть, охватывающая весь мир. Сегодня Интернет имеет десятки миллионов абонентов в большинстве стран мира. Интернет образует как бы ядро, обеспечивающее связь различных формационных сетей одна с другой. Если ранее сеть использовалась исключительно в качестве среды передачи файлов и сообщений электронной почты, то сегодня решаются более сложные задачи распределенного доступа к ресурсам. Сеть Интернет, служившая когда-то исключительно исследовательским и учебным группам, чьи интересы простирались вплоть до доступа к суперкомпьютерам, становится все более популярной в деловом мире. В архивах свободного доступа сети Интернет можно найти информацию по всем сферам человеческой деятельности, начиная с новых научных открытий до прогноза погоды на завтра. Кроме того, Интернет предоставляет уникальные возможности дешевой, надежной и конфиденциальной глобальной связи по всему миру.
Прообраз сети Интернет начал создаваться в конце 1960-х годов по заказу Министерства обороны США. Днем рождения сети Интернет можно считать 2 января 1969 г. В этот день агентство перспективных исследований Министерства обороны США (Advanced Research Project Agency - ARPA) начало работу над проектом связи компьютеров оборонных организаций. В результате выполнения этого проекта была создана сеть ARPANET. При создании сети преследовалось несколько целей, однако одной из основных было создание сети, устойчивой к частичным повреждениям.
К 1986 г. Национальным фондом науки США (National Science Foundarion - NSF) была создана опорная сеть (backbone) для соединения своих шести суперкомпьютерных центров.
Сеть Интернет стала использоваться не только в государственных (учебных и научных) целях, но и в коммерческих. В 1988 г. Интернет становится международной сетью (первыми присоединились Канада, Дания, Финляндия, Франция, Англия, Норвегия, Швеция). К ней стали подключаться страны Европы, Азии и Африки.
Крупнейшей российской сетью является RELCOM, созданная в 1990 г. RELCOM входит в европейское объединение сетей EUNET, которое, в свою очередь, является участником гигантского мирового сообщества Интернет. Такая иерархичность характерна для организации глобальных сетей.
Основное, что отличает Интернет от других сетей, - это ее протоколы - TCP/IP (Transmishion Control Protocol/ Internet Protocol - протокол управления передачей/ сетевой протокол). Свое название протокол TCP/IP получил от двух коммуникационных протоколов (или протоколов связи). Это Transmission Control Protocol (TCP) и Internet Protocol (IP).
TCP сводится к стандартизации следующих процедур:
· разбиение передаваемых данных на пакеты (части);
· адресация пакетов и передача их по определенным маршрутам в пункт назначения;
· сборка пакетов в форму исходных данных.
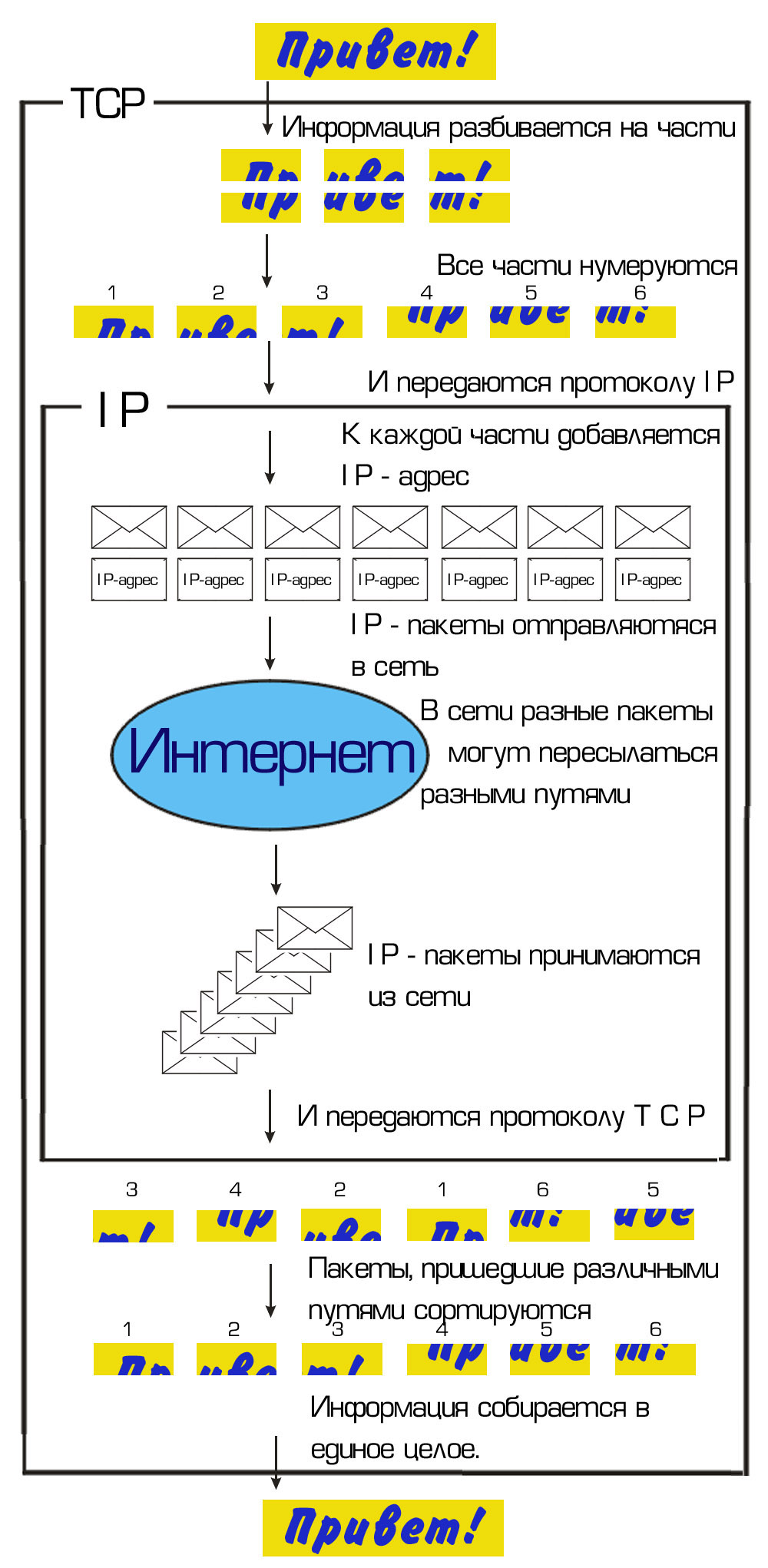
IP отвечает непосредственно за передачу данных по сети и адресацию. На рис. 1 представлена схема передачи данных по протоколу TCP/IP.
Вначале согласно протоколу TCP информация разбивается на части, все части нумеруются и передаются протоколу IP.
Протокол IP добавляет к каждой части IP-адрес назначения. После этого IP-пакеты отправляются в Интернет, при этом разные пакеты могут пересылаться в пункт назначения разными путями, затрачивая разное время. После поступления IP-пакетов в устройство с указанным IP-адресом они поступают на обработку протоколу TCP. IP-пакеты сортируются по номерам, и из разрозненных частей согласно номерам информация собирается в форму исходных данных.
Рис. 1. Схема передачи данных по протоколу TCP/IP
С точки зрения пользователя, Интернет представляет собой совокупность крупных узлов - хост-компьютеров (от англ, host -хозяин) - это один или несколько мощных компьютеров-серверов, объединенных между собой каналами связи. Управляет узлом (или подсетью узлов) его собственник - организация, которая называется провайдером (от английского слова «provide» -обеспечивать) - организация, предоставляющая услуги доступа к Интернету). Хост-компьютеры постоянно находятся во включенном состоянии, постоянно готовы к приему-передаче информации. В таком случае говорят, что они работают в режиме online.
Оnlinе -доступ к сети - доступ, при котором обработка запросов пользователя происходит в режиме реального времени. Доступ, при котором задание для сети готовится заранее, а при соединении происходит лишь передача или прием подготовленных данных, называется Offline. Такой доступ менее требователен к качеству и скорости каналов связи.
Различают два способа подключения к Интернету:
1. удаленный доступ по коммутируемой (переключаемой временной) телефонной линии;
2. прямой доступ по выделенному (постоянному) каналу.
Первый способ значительно дешевле, но менее удобен. Для работы в Интернете нужно предварительно дозвониться по телефону до узла провайдера. Второй способ гораздо эффективнее, но дороже.
Все программное обеспечение, которым можно пользоваться для работы в сети Интернет, можно поделить на две части. Это телекоммуникационные пакеты и абонентское программное обеспечение для работы в сети Интернет.
Телекоммуникационные пакеты используют для подключения к хосту сети, пользуясь обычными телефонными линиями. При этом ему предоставляется возможность работы на одном из хостов сети в режиме online, т.е. пользователь может пользоваться всеми ресурсами узла сети так, как если бы он работал на его терминале.
Абонентское программное обеспечение обеспечивает обслуживание процессов получения и просмотра информации абонентом сети Интернет. Среди огромного количества программ этого назначения наиболее широко известны web-обозреватели Internet Explorer, Netscape Communicator, Opera и Mozilla, пакеты обслуживания почты и новостей Eudora, службы Microsoft Outlock, Outlock Express и др. Использование некоторых из них мы рассмотрим далее.
В основу работы Интернета положено использование прикладных протоколов и технология клиент-сервер. Технология клиент-сервер состоит в следующем: в процессе передачи и обработки информации в сети участвуют два компьютера - запрашивающий (клиент) и выдающий данные по запросу (сервер), при этом работают две программы - программа-клиент и программа-сервер.
Для различных видов обмена документов в Интернете используются следующие прикладные протоколы:
· Telnet - протокол терминального подключения к удаленному компьютеру, исторически был один из первых, сейчас используется редко.
· FTP - file transfer protocol, протокол передачи данных в виде файлов.
· HTTP-hyper text transfer protocol, основной протокол передачи данных в WWW.
· POP, SMTP - post office protocol, simple mail transfer protocol, протоколы передачи электронной почты.
· NNTP - протокол передачи новостей или телеконференций.
· Используя вышеупомянутые протоколы, Интернет предоставляет пользователю следующие сервисы (услуги).
Telnet-сервис, который дает возможность абоненту работать на любом компьютере сети Интернет как на своем собственном, т.е. запускать программы, менять режим работы и т.д. Telnet имеет свой собственный набор команд, которые управляют собственно этой программой, т.е. сеансом связи, его параметрами, открытием новых, закрытием и т.д. Сеанс обеспечивается совместной работой программного обеспечения удаленной ЭВМ и вашей. Они устанавливают TCP-связь и общаются через TCP- и UDP-пакеты.
· FTP-сервис, который определяет правила передачи файловс одного компьютера на другой и дает возможность абоненту обмениваться двоичными и текстовыми файлами с любым компьютером сети.
Электронной почтой (Electronic mail) называется обмен почтовыми сообщениями с любым абонентом сети Интернет.
Archie - система поиска и выдачи информации о расположении общедоступных файлов по анонимному FTP. Система, поддерживающая этот вид услуг, регулярно собирает со своих подопечных (анонимных FTP-серверов) информацию о содержащихся там файлах: списки файлов по каталогам, списки каталогов, а также файлы с кратким описанием того, что в них имеется. Archie позволяет производить поиск по названиям файлов (каталогов) и по описательным файлам, а именно по словам, там содержащимся. Доступ к Archie осуществляется через Archie-серверы, например archie.doc.ic.ac.uk.
Gopher - средство поиска информации в сети Интернет, позволяющее находить информацию по ключевым словам и фразам. Gopher - это индексная система, которая предоставляет доступ к различным услугам Интернета с помощью меню. Работа с системой Gopher напоминает просмотр оглавления, при этом пользователю предлагается пройти сквозь ряд вложенных меню и выбрать нужную тему. Как же отличить станцию Gopher от прочих? Если адрес URL начинается с gopher, а не с http, вы находитесь на станции Gopher. Кроме того, страница Gopher может иметь заголовок типа Gopher Menu и, наконец, третьим признаком является вид меню станций Gopher. Станции Gopher разделены на две группы: одни позволяют искать во всем Gopher-пространстве, а другие - только каталоги. Для упрощения поиска программа Veronica позволяет вводить сложные цепочки поиска, использующие глобальные символы и булевы операторы.
WAIS - диалоговая система с оконным интерфейсом для поиска данных по ключевым словам в контексте. Запросы посылаются в WAIS на упрощенном английском языке. Это значительно легче, чем формулировать их на языке алгебры логики, что делает WAIS более привлекательной для пользователей-непрофессионалов. Версии этой системы (для различных терминалов, операционных систем и машин) можно отыскать в каталоге wais на WAIS-сервере: quake.think.com, вход по имени wais.
Поиск людей (Кто есть кто) - поиск справочной информации о пользователях. Пользователя на известной машине, где он есть, можно отыскать в UNIX-системах с помощью finger. Имеется каталог «белых страниц» Whois, а также одноименная программа для поиска людей. Каталог whois (кто есть кто) поддерживается DDN (Defense Data Network) сетевым информационным центром (Network Information Center - NIC) и содержит более 70000 записей. Команда из UNIX: whois - простейший способ обратиться к таким услугам NIC DDN. С помощью whois - имя (логическое) можно получить информацию о пользователе.
WWW (World Wide Web - всемирная паутина) - сегодня самый популярный и интересный сервис Интернета. WWW работает по принципу клиент-серверы: существует множество серверов, которые по запросу клиента возвращают ему гипермедийный документ - документ, состоящий из частей с разнообразным представлением информации (текст, звук, графика, трехмерные объекты и т.д.), в котором каждый элемент может являться ссылкой на другой документ или его часть. Ссылки эти в документах WWW организованы таким образом, что каждый информационный ресурс в глобальной сети Интернет однозначно адресуется, и документ, который вы читаете в данный момент, способен ссылаться как на другие документы на этом же сервере, так и на документы (и вообще на ресурсы Интернета) на других компьютерах Интернета. Причем пользователь не замечает этого и работает со всем информационным пространством Интернета как с единым целым. Ссылки WWW указывают не только на документы, специфичные для самой WWW, но и на прочие сервисы и информационные ресурсы Интернета. Большинство программ-клиентов WWW (browsers, навигаторы) не просто понимают такие ссылки, но и являются программами-клиентами соответствующих сервисов: FTP, gopher, сетевых новостей Usenet, электронной почты и т.д. Таким образом, программные средства WWW являются универсальными для различных сервисов Интернета, а сама информационная система WWW играет интегрирующую роль.
Для обеспечения интерактивного общения пользователей сети используются сервисы: чаты, MUD, MOO, Internet Phone.
IRC - Internet Relay Chat, разговоры через Интернет. В Интернете существует сеть серверов IRC. Пользователи присоединяются к одному из каналов - тематических групп и участвуют в разговоре, который ведется текстом. Узлы IRC синхронизованы между собой, так что подключившись к ближайшему серверу, вы подключаетесь ко всей сети IRC.
Подобную функциональность несут еще два сервиса - MUD и МОО. Расшифровываются эти аббревиатуры как Multi User Dungeon (многопользовательская игра) и Object-Oriented MUD (объектно-ориентированный многопользовательский мир).
Internet Phone (телефония) - быстро развивающийся новый вид услуг, использующий принцип голосовой связи. С помощью данной услуги возможна передача голоса, видеоизображения, обмен текстовыми сообщениями, совместное использование графического редактора, обмен файлами.
Java-технологии. Интернет - очень быстро развивающаяся сеть. Причина этого заключена не только в свойствах Интернета, но и в общих тенденциях развития компьютерной индустрии. Одним из перспективных и многообещающих направлений развития Интернета и сетевых технологий в целом является Java.
Java - интерпретируемый язык с синтаксисом C++, специально рассчитанный на работу в открытой сетевой среде. Текст программы на языке Java может компилироваться в бинарный псевдокод и передаваться по сети для исполнения на виртуальной машине в удаленном интерпретаторе. При этом доступ к ресурсам машины, на которой он работает, для Java-программы может быть ограничен с целью обеспечения безопасности.
Такие передаваемые по сети маленькие программы на языке Java называются аплетами. С серверов Интернета могут вызываться не только программы, но и описания объектов или форматов данных. Чтобы пользоваться возможностями, предоставляемыми языком Java, ваш WWW-обозреватель должен уметь вызвать для исполнения аплетов Java-интерпретатор. Первый такой навигатор был выпущен компанией Sun для операционной системы Solaris и назывался HotJava. Вскоре и Netscape Navigator стал поддерживать Java на ряде платформ, и в частности в Windows. Это обеспечило еще больший успех Java. Поддержку языка Java обеспечивают современные версии web-обозревателей Microsoft Internet Explorer и Opera, причем Opera напрямую использует Java Runtime Environment (JRE) вместо плагинов для запуска Java-апплетов. Вполне вероятно, что скоро поддержку этого сетевого языка будут обеспечивать все WWW-навигаторы, а значит, и многие серверы. А если Java сможет приобрести достаточную популярность и стать стандартом де-факто, то весь Интернет и вся компьютерная технология вообще выйдут на качественно новый уровень развития, когда ресурсы компьютеров всего мира будут объединены в один компьютер под названием Сеть.
Java позволит решить самые глубокие проблемы WWW: отсутствие интерактивности, ограниченный контроль вида документа, ограниченный набор форматов встроенной графики и других объектов мультимедиа. Если вы создаете документ в Интернете и используете язык Java, то, включив в документ картинку в придуманном вами формате, вы можете также указать ссылку на программу, которая умеет читать ваш формат и рисовать картинку. Если вас не устраивают существующие протоколы передачи данных в Интернете, то вы можете определить свой протокол и передавать данные по нему, предварительно указав ссылку, откуда брать программу для его поддержки.
WWW-навигатор, поддерживающий язык Java, неограниченно расширяем и позволяет реализовать все, что угодно. При этом замечательна та особенность, что с точки зрения пользователя все предельно просто - он пользуется стандартным интерфейсом, не замечая никаких сложностей с форматами, протоколами и т.д.
Сегодня Java применяется для передачи через Интернет аплетов, маленьких программ, обычно реализующих простые вещи для украшения WWW-страниц. Однако возможности и перспективы проекта Java уходят далеко за горизонты WWW. Принципиально новой идеей является передача через Интернет не просто данных, но приложений. Новая технология сделала документы объектами, вместе с которыми стали передаваться и методы их обработки. Это предоставляет возможность построения средствами Java больших программных продуктов, полностью использующих возможности современных корпоративных информационных сред, построенных на базе высокоскоростных сетей и мощных серверов баз данных в архитектуре клиент-сервер.
Virtual Reality Modeling Language (VRML). Аббревиатура VRML расшифровывается как «язык описания виртуальной реальности». Это язык подобен HTML, но описывает графические трехмерные объекты за счет перечисления используемых в сцене примитивов и их координат. Позволяет создавать сложные сцены с наложением текстур, установкой источников цвета и камер. Через World Wide Web пользователь может получить файл в формате VRML и, если программа-клиент обладает такой возможностью, просматривать сцену с разных точек зрения. Картинка на экране остается плоской, но, перемещая точку обзора, можно наблюдать вид трехмерного объекта с разных сторон.
Стереоизображения. Стереоизображения - это, как и VRML, попытка добавить к различным формам мультимедиа еще одну -трехмерное изображение, но с несколько другой стороны. Если VRML передает информацию о трехмерных объектах, отображая ее двумерно, т.е. определяет способ передачи информации, то стереографика пытается решить задачу объемной визуализации объектов, т.е. представления информации.
Уже сегодня в Интернете имеются коллекции стереокартинок, смотреть которые можно без дополнительного оборудования путем перефокусировки зрения. Вы фокусируете взгляд на воображаемой точке за поверхностью изображения так, что картинка, раздваиваясь, совмещается особым образом сама с собой, что дает визуальный эффект трехмерного изображения. Так как использование такой технологии вредно для глаз, для получения объемного изображения применяется дополнительное оборудование. В простейшем варианте это просто очки, разделяющие каким-либо образом изображение между глазами, например при помощи цвета. Двухцветные очки - простейший случай, поскольку они очень просты сами по себе и не требуют аппаратных изменений компьютера. Такой вариант сегодня уже практикуется в компьютерных играх. Он весьма прост, дешев и результативен. Другим методом, реализованным в играх, является присоединение к компьютеру специального шлема. Такой метод хорош тем, что не требует никакого дополнительного оборудования, кроме самого шлема, и аппаратных изменений компьютера. С другой стороны, он обеспечивает полный контроль над информацией, воспринимаемой зрительно, что имеет свои плюсы и минусы. Третья, наименее развитая, технология - использование поляризационных очков. Она, возможно, наиболее перспективна, но наименее развита, поскольку требует изменений аппаратной части компьютера.
В 1991 г. физик Тим Бернерс-Ли из Женевского ЦЕРНа (Европейской лаборатории физики элементарных частиц) предложил создать систему, которая позволяла бы всем физикам в Европе обмениваться по Интернету результатами своих исследований в виде иллюстрированного текста, включающего ссылки на другие публикации. Так было положено начало WWW. Технология WWW состоит из четырех компонентов:
· язык гипертекстовой разметки документов HTML (Hyper-Text Markup Language);
· универсальный способ адресации ресурсов в сети URL (Universal Resource Locator);
· протокол обмена гипертекстовой информацией HTTP(HyperText Transfer Protocol);
· универсальный интерфейс шлюзов CGI (Common GatewayInterface).
1. Идея HTML - пример чрезвычайно удачного решения проблемы построения гипертекстовой системы при помощи специального средства управления отображением. На разработку языка гипертекстовой разметки существенное влияние оказали два фактора: исследования в области интерфейсов гипертекстовых систем и желание обеспечить простой и быстрый способ создания гипертекстовой базы данных, распределенной на сети. Фактически в настоящее время HTML развивается в сторону создания стандартного языка разработки интерфейсов как локальных, так и распределенных систем.
2. Вторым компонентом WWW стала универсальная форма адресации информационных ресурсов. Universal Resource Identification (URI) представляет собой довольно стройную систему, учитывающую опыт адресации и идентификации e-mail, Gopher, WAIS, telnet, FTP и т.п. Для организации баз данных в WWW требуется Universal Resource Locator (URL). B URL можно адресовать как другие гипертекстовые документы формата HTML, так и ресурсы e-mail, telnet, FTP, Gopher, WAIS.
3. Третьим компонентом World Wide Web является протокол обмена данными – Hyper Text Transfer Protocol (HTTP). Данный протокол предназначен для обмена гипертекстовыми документами и учитывает специфику такого обмена. Так, в процессе взаимодействия клиент может получить новый адрес ресурса на сети(relocation), запросить встроенную графику, принять и передать параметры и т.п.
4. Последняя составляющая технологии WWW - спецификация Common Gateway Interface. CGI была специально разработана для расширения возможностей WWW за счет подключения всевозможного внешнего программного обеспечения. Такой подход логично продолжал принцип публичности и простоты разработки и наращивания возможностей WWW. Предложенный и описанный в CGI способ подключения не требовал дополнительных библиотек. Сервер взаимодействовал с программами через стандартные потоки ввода/вывода, что упрощает программирование до предела. Программа, написанная в соответствии со спецификацией Common Gateway Interface, называется CGI-скрип-том. CGI-скрипты могут быть написаны на любом языке программирования (С, C++, PASCAL, FORTRAN и т.п.) или командном языке (shell, cshell, командный язык MS-DOS, Perl и т.п.).
WWW часто называют распределенной информационной системой мультимедиа, основанной на гипертексте. Определение распределенная означает, что информация не сконцентрирована на одном компьютере, а распределена на огромном множестве компьютеров. Слово «мультимедиа» включено в определение, так как информация включает не только текст, но и 2-3-мерную графику, видео, звук, анимацию. Как показано на рис. 2, гипертекст - это структурированный текст, в котором могут осуществляться переходы по выделенным меткам - гиперссылкам.
Наименьший документ WWW, имеющий собственный адрес, называется web-страницей. Расширение файла, являющегося web-страницей, - *.html или *.htm.
Группа web-страниц, объединенных одной темой, называется web-узлом (сайтом). Обычно сайт имеет титул - головную страницу, от которой по гиперссылкам или указателям «вперед-назад» можно двигаться по страницам сайта.
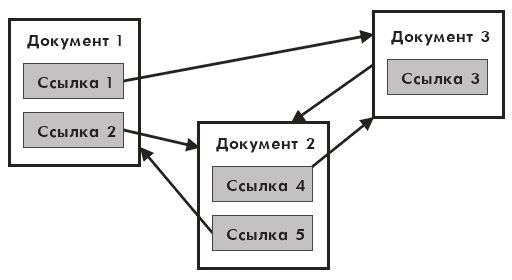
Рис. 2. Схема гиперссылок в гипертексте из трех документов
Примечание. Гиперссылка - выделенная область документа (например, часть текста, фото, картинка, кнопка и т.д.), позволяющая переходить к другому документу, содержащая связанную информацию.
Web-сайты размещаются на WWW-серверах - компьютерах, принадлежащих отдельным организациям и частным лицам. С помощью гипертекстовых ссылок, встроенных в документы WWW, пользователь может быстро переходить от одного документа к другому, от сайта к сайту, от сервера к серверу.
Для работы с WWW используются специальные программы-клиенты, которые по-английски называются browsers (browsers-от английского глагола "browse" - просматривать), а по-русски - браузерами, навигаторами, обозревателями, просмотрщиками. Наиболее популярные в настоящий момент браузеры Microsoft Internet Explorer, Netscape Navigator и Opera. Основная задача браузера - обращение к web-серверу за искомой страницей и вывод страницы на экран. Простейший способ получения нужной информации из Интернета - указание адреса искомого ресурса.
Как вы уже знаете, для связи компьютеров в сети каждому компьютеру присваивается числовой адрес. Но для удобства пользователей компьютерам в Интернете были присвоены собственные имена. Для указания адреса информационного ресурса в Интернете используются несколько систем имен. Наиболее широко распространена региональная система имен, которая очень похожа на почтовые адреса. Сетевые числовые адреса вполне аналогичны почтовым индексам, которые мы надписываем на конвертах. Машины, сортирующие корреспонденцию на почтовых узлах, ориентируются именно по индексам, и только если с индексами выходит какая-то несуразность, передают почту на рассмотрение людям, которые по адресу могут определить правильный индекс почтового отделения места назначения. Людям же приятнее и удобнее иметь дело с географическими названиями - это аналоги доменных имен.
Конечно, такое именование имеет свои собственные проблемы. Прежде всего, следует убедиться, что никакие два компьютера, включенные в сеть, не имеют одинаковых имен. Нужно также обеспечить преобразование имен в числовые адреса, для того чтобы машины (и программы) могли понимать нас, пользующихся именами.
Вначале сеть Интернет была небольших размеров и иметь дело с именами было довольно просто. На узле сети была создана регистратура, куда можно было послать запрос и в ответ получить файл - список имен и адресов. Этот файл, называемый «host file» (файл рабочих ЭВМ), регулярно распространялся по всей сети -рассылался всем машинам. Но по мере развития и расширения Интернета возрастало количество пользователей, хостов, а потому увеличивался и упомянутый файл. Возникали значительные задержки при регистрации и получении имени новым компьютером, стало затруднительно изыскивать имена, которые еще никто не использовал, слишком много сетевого времени затрачивалось на рассылку этого огромного файла всем машинам, в нем упомянутым. Стало очевидно, чтобы справиться с такими темпами изменений и роста сети, нужна распределенная оперативная система, опирающаяся на новый принцип. Так была создана «доменная система имен» - DNS (Domain Name System). DNS часто называют региональной системой наименований.
Система доменных адресов строится по иерархическому принципу. Каждый уровень этой системы называется доменом. Фактически нет единого корня всех доменов Интернета. В 80-е годы XX в. в США были определены первые домены верхнего уровня: образовательных (edu), коммерческих (com), государственных (gov), военных (mil) учреждений, а также сети других организаций (org) и сетевых ресурсов (net).
Когда сеть Интернет перешагнула национальные границы США, появились национальные домены. Сейчас принята двух-буквенная кодировка государств. Это оговорено в инструкции RFC 822. Так, например, домен Чехия называется cz, бывший СССР - su, США - us, Россия - ru и т.д. США также включили в эту систему структурирования для всеобщности и порядка. Всего же кодов стран почти 300, из которых около 100 имеет компьютерную сеть того или иного рода. Единый каталог Интернета находится у SRI International (Менло-Парк, Калифорния, США) -государственной организации.
Вслед за доменами верхнего уровня следуют домены, определяющие либо регионы (msk, vrn), либо организации (kiae, fio). Далее идут следующие уровни иерархии, которые могут быть закреплены либо за небольшими организациями, либо за подразделениями больших организаций.
Домены в именах отделяются друг от друга точками, например: inr.msk.su, nusun.jinr.dubna.su, arty.bashkiria.su, vxcern.cern.ch, nic.ddn.mil, vrn.fio.ru. В имени может быть различное количество доменов, но практически их не больше пяти. По мере движения по доменам слева направо в имени количество имен, входящих в соответствующую группу, возрастает.
Первым в имени стоит название рабочей машины - реального компьютера с IP-адресом. Это имя создано и поддерживается группой (например, компьютер nusun (это SUN spare) в группе jinr (ОИЯИ)), к которой он относится. Группа входит в более крупное подразделение (например, городское объединение - сеть города Дубны), которое, в свою очередь, является частью национальной сети (например, сети стран бывшего СССР, домен su). Группа может создавать или изменять любые, ей подлежащие имена. Если jinr решит поставить другой компьютер и назвать его mainx, он ни у кого не должен спрашивать разрешения. Все, что от него требуется, - это добавить новое имя в соответствующую часть соответствующей всемирной базы данных, и, рано или поздно, каждый, кому потребуется, узнает об этом имени. Аналогично, если в Дубне решат создать новую группу, например schools, они (домен dubna) могут это сделать также, ни у кого не спрашивая никакого соизволения. Тогда, если каждая группа придерживается таких простых правил и всегда убеждается, что имена, которые она присваивает, единственны во множестве ее непосредственных подчиненных, то никакие две системы, где бы те ни были в сети Интернет, не смогут заиметь одинаковых имен. Таким образом, доменное имя однозначно определяет компьютер в сети Интернет.
Для хранения и поиска информации в Интернете используется универсальная адресация, которая носит название URL -Uniform Resource Locator. UPL-адрес состоит из трех частей: используемый протокол; доменный адрес узла; путь доступа к файлу. <имя протокол а>://адрес компьютера> {/<путь к документу>}. Например,
· http://HMH сервера/путь к файлу
· http://www.gov.ru - web-сайт органов государственной власти Российской Федерации;
· http://info.isoc.org/guest/zakon/Internet/History/HIT.html - адрес web-документа «История Интернета»;
· http://www.eff.org/pub/Net_info/EFF_Net_Guide/Other_versions/ Russian/ - адрес web-документа «Руководство по глобальной компьютерной сети Интернет».
Поиск адреса по доменному имени. Зная как соотносятся домены и создаются имена, вы теперь можете представить, как автоматически можно использовать эту систему. Старт поиска адреса задается, как только вы употребите имя на компьютере, который понимает, как обращаться с DNS. Все компьютеры Интернета способны пользоваться доменной системой. Работающий в сети компьютер всегда знает свой собственный сетевой адрес. Когда вы пользуетесь именем, например, mx.ihep.su, компьютер должен преобразовать его в адрес. Для этого он начинает запрашивать помощь у DNS-серверов. Это узлы, рабочие машины, обладающие соответствующей базой данных, в число обязанностей которых входит обслуживание такого рода запросов. DNS-сервер начинает обработку имени с правого его конца и двигается по нему влево, т.е. сначала производится поиск адреса в самой большой группе (домене), потом постепенно сужает поиск. Но для начала опрашивается на предмет наличия у него нужной информации местный узел. Здесь возможны три случая.
1. Местный сервер знает адрес, потому что этот адрес содержится в его части всемирной базы данных. Например, если вы подсоединены к сети Института физики высоких энергий (ШЕР),то ваш местный сервер должен обладать информацией обо всех компьютерах локальной сети этого института (mx, desert, ixwinи т.д.).
2. Местный сервер знает адрес, потому что кто-то недавно уже запрашивал тот же адрес. Когда запрашивается адрес, сервер DNS запоминает его у себя в памяти некоторое время - это повышает эффективность системы.
3. Местный сервер адрес не знает, но знает, как его выяснить.
В его прикладном или системном программном обеспечении имеется информация о том, как связаться с корневым сервером. Это сервер, который знает адреса серверов имен высшего уровня (самых правых в имени), здесь это уровень государств (ранга домена su, ru, com, gov, org). У него запрашивается адрес компьютера, ответственного за зону su. Местный DNS-сервер связывается с этим более общим сервером и запрашивает у него адрес сервера, ответственного за домен ihep.su. Теперь уже запрашивается этот сервер и у него запрашивается адрес рабочей машины mx.
На самом деле для повышения эффективности поиск начинается не с самого верха, а с наименьшего домена, в который входите и вы, и компьютер, имя которого вы запросили. Например, если ваш компьютер имеет имя nonlin.mipt.su, то опрос начнется (если имя не выяснится сразу) не с всемирного сервера, чтобы узнать адрес сервера группы su, а с группы su, что сразу сокращает поиск и по объему, и по времени.
Этот поиск адреса совершенно аналогичен поиску пути письма без надписанного почтового индекса. Как определяется этот индекс? Все регионы пронумерованы - это первые цифры индекса. Письмо пересылается на центральный почтамт этого региона, где имеется справочник с нумерацией районов этого региона - это следующие цифры индекса. Теперь письмо идет на центральный почтамт соответствующего района, где уже знают все почтовые отделения в подопечном районе. Таким образом, по географическому адресу определяется почтовый индекс, ему соответствующий. Также определяется и адрес компьютера в Интернете, но путешествует не послание, а запрос вашего компьютера об этом адресе.
Если ваш компьютер имеет подключение к Интернету и оснащен операционной системой Windows 98/2000/XP, то ее стандартное приложение Интернет Explorer обеспечивает возможность поиска информации в Интернете из любого места на компьютере. Такая возможность обеспечивается наличием в Интернете поисковых серверов.
Поисковыми серверами называют выделенные компьютеры, которые автоматически просматривают все ресурсы Интернета и индексируют их содержание. Затем вы можете передать такому серверу фразу или набор ключевых слов, описывающих интересующую вас тему, и сервер возвратит вам список ресурсов, соответствующих вашему запросу. Современные поисковые системы поддерживают индексы, включающие значительную часть ресурсов Интернета. Таких серверов существует довольно много, например: InfoSeek (www.infoseek.com), AltaVista (www.altavista.com); российские поисковые серверы: Апорт (www.aport.ru), Rambler (www.rambler.ru), Яндекс (www.yandex.ru) и др. Если в Интернете есть информация, которая вас интересует, то ее наверняка можно найти при помощи поисковых серверов.
Задавая образ поиска в поисковой системе, следует иметь в виду, что алгоритмы поиска информации в сети, подобно поиску информации в базе данных, основаны на логике.
1. Несколько ключевых слов, разделенных пробелом, соответствуют операции логического сложения: ИЛИ (OR). Например, указав ключ: <Школьная информатика>, мы получим список всех документов, в которых встречается слово «Школьная» или слово «информатика».
2. Несколько слов, заключенных в кавычки, воспринимаются как единое целое. Например, «Школьная информатика».
3. Знак + между словами равносилен операции логического умножения: И (AND). Указав в запросе ключ <Школьная + информатика>, получим все документы, в которых имеются эти два слова одновременно, но они могут быть расположены в любом порядке и в разброс.
Нахождение информационных ресурсов в каталогах. В каталогах Интернета хранятся тематически систематизированные коллекции ссылок на различные сетевые ресурсы, в первую очередь на документы World Wide Web. Ссылки в такие каталоги заносятся не автоматически, а их администраторами. Занимающиеся этим люди стараются сделать свои коллекции наиболее полными, включающими все доступные ресурсы на каждую тему. В результате пользователю не нужно самому собирать все ссылки по интересующему его вопросу, но достаточно найти этот вопрос в каталоге - работа по поиску и систематизации ссылок уже сделана за него.
Каталоги обычно имеют древовидную структуру и похожи на очень большой список закладок. Когда World Wide Web только начинала развиваться и ее серверы еще можно было пересчитать, некоторые пользователи вели их списки. Со временем WWW-серверов становилось все больше, каждый день появлялись новые, и механизма закладок стало недостаточно для того, чтобы хранить эту информацию. Некоторые пользователи WWW стали создавать специальные программы для поддержания базы данных по ссылкам на ресурсы Интернета, ее автоматической синхронизации и управления ею. Именно так и родились глобальные каталоги сети, как, например, Yahoo! (www.yahoo.com), Lycos (www.lycos.com), российский каталог ресурсов List (www.list.ru) и др.
Как правило, хорошие каталоги сети Интернет обеспечивают разнообразный дополнительный сервис: поиск по ключевым словам в своей базе данных, списки последних поступлений, списки наиболее интересных из них, выдачу случайной ссылки, автоматическое оповещение по электронной почте о свежих поступлениях.
Существуют также специализированные поисковые серверы:
1. Поиск E-mail, адресов и людей/компаний: Fourl I Directory, Lookup, Nynex Inreactive Yellov Pages for business, Phone Directory.
2. Поиск программного обеспечения: FTP Search, Snoopie, Jumbo.
3. Поиск в телеконференциях: DejaNews.
4. МЕТАПОИСК-универсальный метод поиска: SavvySearch, All-in-One Search Page, Metasearch, Searchers, Starting Pointmetasearch, W3 Search Engines.
На многих информационных серверах имеются ссылки на такие поисковые серверы.
Поиск информации на отдельном web-узле. Каждому пользователю Интернета часто приходится решать задачу поиска информации на отдельном web-узле. Если вы связываетесь с Интернетом через модем, то, очевидно, что чем больше вы тратите времени на поиски, тем дороже стоит получаемая информация. Следовательно, умение быстро разобраться в структуре узла и способах навигации (т.е. путей перемещения с одной web-страницы узла на другую) становится полезным навыком.
Для быстрого поиска информации на web-узле можно предложить следующие варианты:
· а) путем начального задания адреса вручную в строке URL(Адрес) или выбора документа из списка истории браузера (программы просмотра web-страниц), если таковая уже накоплена;
· б) по гипертекстовым ссылкам;
· в) по каталогам узла с помощью обрезания строки ранее введенного адреса (URL), последовательно поднимаясь от каталога к каталогу вверх к корню сервера.
Один из самых эффективных способов ускорения работы с web-страницей - это активное использование средств автоматического поиска. Такой подход особенно практичен для многоэкранных страниц с информационных узлов, когда визуальное ознакомление с материалом становится слишком трудоемким. Поиск на странице можно произвести по терминам, введенным в специальный поисковый шаблон, который активизируется в браузерах клавишами Ctrl+F или через меню Правка-Поиск на этой странице или нечто подобное.
Примечания:
1. Поиск на web-странице всякий раз проводится вверх или вниз по странице в зависимости от указания направления в шаблоне, начиная с начала (если вниз) или с конца документа (если вверх), независимо от того, какая часть страницы отображается на экране на момент начала поиска.
2. Допустимо введение в шаблон не только единичного термина, но и фразы, что делается одной строкой без использования специального синтаксиса. Специальная пометка в шаблоне позволяет искать с учетом регистра символов.
3. Найденное слово или фраза выделяются в тексте, и происходит автоматическое перемещение к их местоположению, однако выделенное поле не всегда можно наблюдать.
4. Если при старте поиска уже есть выделенная область текста, то поиск начинается именно с нее в заданном в шаблоне направлении, само содержимое выделенного поля участия в поиске уже не принимает, так же как и оставшаяся часть страницы. Отметим, что всякий раз, когда поисковая процедура закончена, на странице остается выделенная область текста, соответствующая последнему совпадению. Если необходимо выполнить поиск с новыми терминами, то следует сначала снять уже существующее выделение кликом мыши в любой точке текста, иначе в новом поиске будет участвовать только часть страницы вверх или вниз от выделенной области в зависимости от направления, заданного в шаблоне.
5. Надписи, выполненные в графике, не откликаются на поисковые запросы.
6. Если при проведении поиска экран разделен на фреймы, то обсуждаемые нами браузеры работают по-разному. Internet Explorer объединяет документы из разных фреймов в единое текстовое поле, в котором и производит последовательный поиск после активизации пункта меню Найти на этой странице, т.е. автоматически переходит из фрейма во фрейм. Netscape Navigator имеет специальную возможность поиска внутри заданного фрейма.
Основное меню узла, которое обычно расположено слева или вверху экрана, довольно часто содержит надписи, которые выполнены в виде графики, т.е. представляют собой рисованные объекты, а не алфавитно-цифровой набор символов, введенных с клавиатуры. Поэтому, как было указано выше, нельзя локализовать термины из графического меню с помощью функции поиска по странице. Однако чтобы не лишать пользователя такой возможности, часто разработчики дублируют заголовки графического меню в самом низу web-страницы в символьном режиме.
При задании образа поиска нужно помнить о том, что глоссарий терминов, соответствующих определенному типу информации, может отличаться в зависимости от профиля изучаемых ресурсов. Также важно, что на web-страницах распространена специфичная сетевая лексика в связи с тем, что в Интернете доминируют авторы, имеющие техническое образование или, по крайней мере, «технократический» образ мышления, которым свойственны лаконичность, колорит и, увы, порочное тяготение к сленгу.
Разумеется, чем ближе профиль материала к техническим проблемам и чем фамильярней изложение, тем выше доля сленговой лексики. Так, например, если сайт предназначен для представления программного обеспечения, то раздел, содержащий новые поступления, скорее будет называться не «Новые программы», а «Свежий софт».
На многих серверах предусмотрена страница, которая предлагает более детальное изложение его содержания, чем основное меню. Такая страница называется «Карта сервера» («Site map»).
Аналогично используют функцию поиска по странице для того, чтобы найти ссылку на локальную поисковую машину, если она организована разработчиком узла. Тогда после нажатия Ctrl+F следует ввести в шаблон слово «поиск» («search»), и ссылка будет найдена в течение секунды.
Для более специализированных узлов целесообразно выработать собственную тактику выбора значимых терминов: важно не просто знать как то, что вы разыскиваете, называется по-русски или по-английски, а как это называется в Интернете.
Еще одно замечание сделаем относительно возможности еще до нажатия на гиперссылку отследить адрес (URL), по которому она осуществит переход. Когда указатель мыши встает на ссылку (без нажатия), то в строке состояния браузера появляется соответствующий адрес. Эту информацию можно использовать для предварительной оценки целесообразности такого перехода, она также полезна и в случае применения разработчиком специальной графической карты гипертекстовых ссылок (UsemapClient Side), когда отдельные фрагменты сомкнутой воедино картинки могут являться ссылками на различные ресурсы.
Для просмотра ресурсов Интернета нужно сначала соединиться с Интернет-провайдером. Для соединения имеется большое количество программ. Один из самых распространенных вариантов подключения к Интернету через модем из среды Windows -подключение через удаленный доступ, порядок настройки которого подробно описан в справке Windows. Для соединения с Интернет-провайдером откройте окно Удаленный доступ к сети и щелкните ярлык удаленного доступа, затем выберите номер соединения, введите имя пользователя, пароль и щелкните кнопку «Вызов», например как показано на рис. 3.
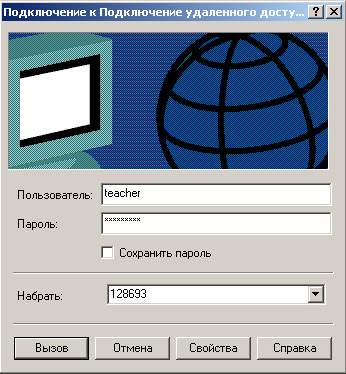
Рис. 3. Попытка соединения с Интернет-провайдером
После этого модем вашего компьютера набирает номер телефона канала связи вашего Интернет-провайдера. В случае неудачи попытка соединения будет повторена. Если соединение установлено, то в панели задач будет выведен значок, щелкнув который, можно просмотреть параметры сеанса связи: скорость, длительность сеанса, объем информации; щелкнув на кнопке «Отмена», разорвать соединение с Интернет-провайдером.
Хотя все гипермедийные документы web и предназначены для всех желающих, просто подсоединиться к web и начать их читать нельзя, так как web-документы существуют в виде файлов особого HTML-формата. Нужна программа, которая преобразует документ в нечто, что ваш компьютер может понять и вывести на экран. Такая программа называется средством просмотра web или Интернет-обозревателем, браузером.
Наиболее популярны среди пользователей Интернет-браузеры Microsoft Internet Explorer, Netscape Communicator, Opera.
Версия Netscape Communicator включает браузер, почтовый клиент, редактор web-страниц, программу общения AOL Instant Messenger, проигрыватели RealPlayer G2 и WinAmp, а также имеет встроенную поддержку Shockwave и Flash.
Бесплатная русскоязычная версия браузера Opera, получившего широкую известность за скорость работы и удобный интерфейс с множеством настроек, включает почтовый клиент, клиент конференций, новостей и программу общения, совместимую с ICQ. Встроенная в Opera функция OperaShow позволяет использовать HTML-документы для презентаций.
Фирма Microsoft выпускает целое семейство программ для работы в Интернете.
1. Обозреватель Internet Explorer - программа просмотра документов WWW, локальной сети или интрасети.
2. Программа для обмена сообщениями и работы с группами новостей Outlook Express.
3. Программа Net Meeting - средство проведения конференций через Интернет или в локальной сети с возможностями вызова, передачей голоса и видеоизображения.
4. Программа Net Show, позволяющая воспроизвести в Интернете мультимедийные документы.
5. Программа Font Page Express - редактор документов на языке HTML.
С целью экономии времени и средств оплаты за время доступа в Интернет используется загрузка и сохранение отдельных web-страниц и целых сайтов на винчестере вашего компьютера, чтобы затем, отключившись от Интернета, можно было спокойно заниматься их изучением.
Такие возможности предоставляются пользователю программой Microsoft Internet Explorer версии 5.0 и выше. Для того чтобы решить проблему сохранения связей между ссылками внутри отдельных страниц, Internet Explorer 5.0 имеет диспетчер синхронизации страниц. Суть метода в том, что Internet Explorer выполнит за вас все переходы по ссылкам, размещенным на стартовой странице, на указанную глубину. Для того чтобы закачать к себе весь сайт или его часть, нужно в первую очередь иметь представление, на какую глубину расположены его ссылки. Для этого можно воспользоваться либо картой сайта, если она есть, либо использовать средство построения карты Naviscope.
Примечание. В большинстве случаев достаточно глубины 3.
Следует понимать, что web-обозреватель тупо пройдется по всем без исключения ссылкам (в том числе и рекламным), загрузит все архивы, на которые есть прямые ссылки, поэтому через некоторое время у вас на диске может оказаться пол - Интернета. Поэтому не пытайтесь скачивать таким образом каталоги (типа List.Ru) или сайты электронных СМИ (типа Citforum.Ru) и перед началом синхронизации постарайтесь получить представление о структуре сайта.
Потом, отключившись от Интернета, в Offline-режиме сможете спокойно все загруженное просмотреть.
К сожалению, использование Internet Explorer для загрузки и сохранения целых сайтов на винчестере компьютера имеет ряд недостатков: низкая скорость загрузки web-страниц; проблемы, связанные с разрывом dial-up-соединения; отсутствие избирательной загрузки элементов и т.п.